structure-informed positional encoding for music generation
This is the companion website to our ICASSP 2024 paper: Structure-informed Positional Encoding for Music Generation.
📢 NEW! Our paper was selected for an oral presentation! If you are at ICASSP 2024, you can find us presenting this work at session AASP-L2 in Room 105 at 17:50 on Tuesday, April 16, 2024. See you in Seoul!
💻 Code: GitHub
💾 Dataset: Zenodo
📔 Paper: arXiV HAL IEEE
🔗 DOI: 10.1109/ICASSP48485.2024.10448149
Contents
- Training Details
- Dataset Supplement
- Generated Samples
- Next-timestep Prediction: jump to good examples (Baselines, Our Methods) and bad examples (Baselines, Our Methods)
- Accompaniment Generation: jump to good examples (Baselines, Our Methods) and bad examples (Baselines, Our Methods)
Training Details
We use a Transformer decoder with 2 layers, 4 heads and 512 dimension size. We use a batch size of 8 and 15 epochs for training. During training, we use two learning rate schedulers: one linearly warms-up the learning rate for the first few batches of the first epoch and the other decays the learning rate by a factor of 0.85 at the end of each epoch. We use curriculum learning on the sequence length. This means that we gradually increase the length of the training samples to the required sequence length for the first three epochs. We optimize the learning rate as a hyperparameter with grid-search over the choices: 5e-5, 1e-4, 2e-4, 5e-4, 1e-3. Further, we also treat the binarization strategy described in the paper as a hyperparameter and choose the best method by simple grid-search over the following options:
- Threshold:
- Possible thresholds: 0.2, 0.4, 0.5, 0.6, 0.8
- Threshold + merge:
- Possible thresholds: 0.2, 0.4, 0.5, 0.6, 0.8
- Possible merge distances: 2, 4, 6, 8, 10, 12, 14
- Top-k sampling:
- Possible choices for k: 2, 3, 4, 5, 6, 7, 8, 9, 10
- Top-k sampling + merge:
- Possible choices for k: 3, 4, 5, 6
- Possible choices for merge distances: 2, 4, 6, 8
Dataset Supplement
The dataset we use is the Chinese POP909 dataset, which comes with structural annotations. The MIDI songs are cleanly divided into three tracks: melody, bridge and piano. We first convert them into pianorolls. We select only those songs with a 4/4 time signature and that are long enough to provide at least one sample, giving us a total of 866 songs.
The structural labels contain four categories for each timestep, with each category corresponding to a different temporal resolution: tempo, section, chord and melody. However, these annotations are not properly aligned with the MIDI file due to two sources of variable-length error:
- silence at the beginning of the song
- musical phrases that are not included in the labeling, such as pickup measures
Although the first source of error is trivial to eliminate, the second cannot be corrected with high precision in an automated fashion. Hence, I manually select the beat position at which the structural annotations should start for each song. Below, I show the validation loss for a selection of baselines and proposed methods, using 20% of the dataset.
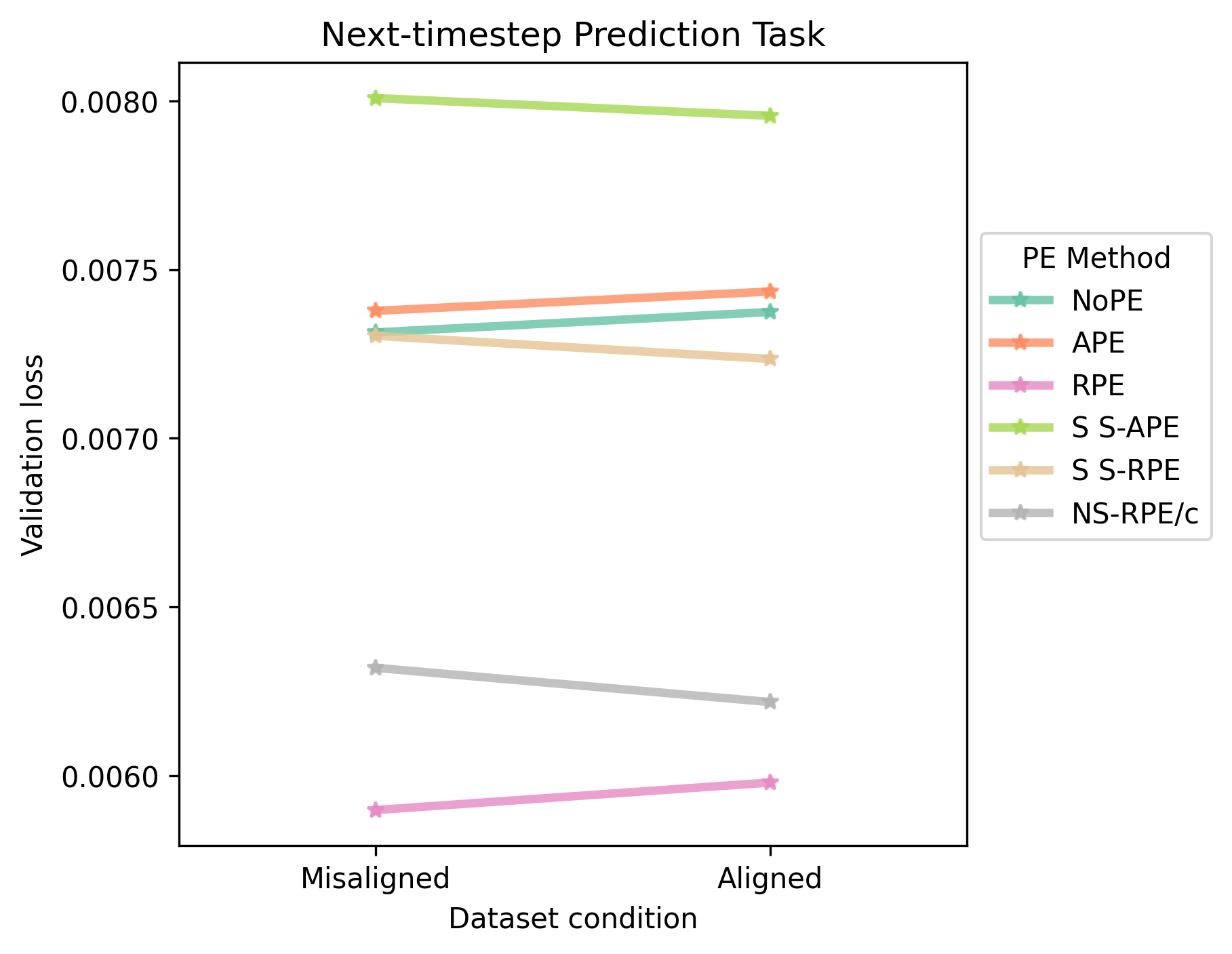
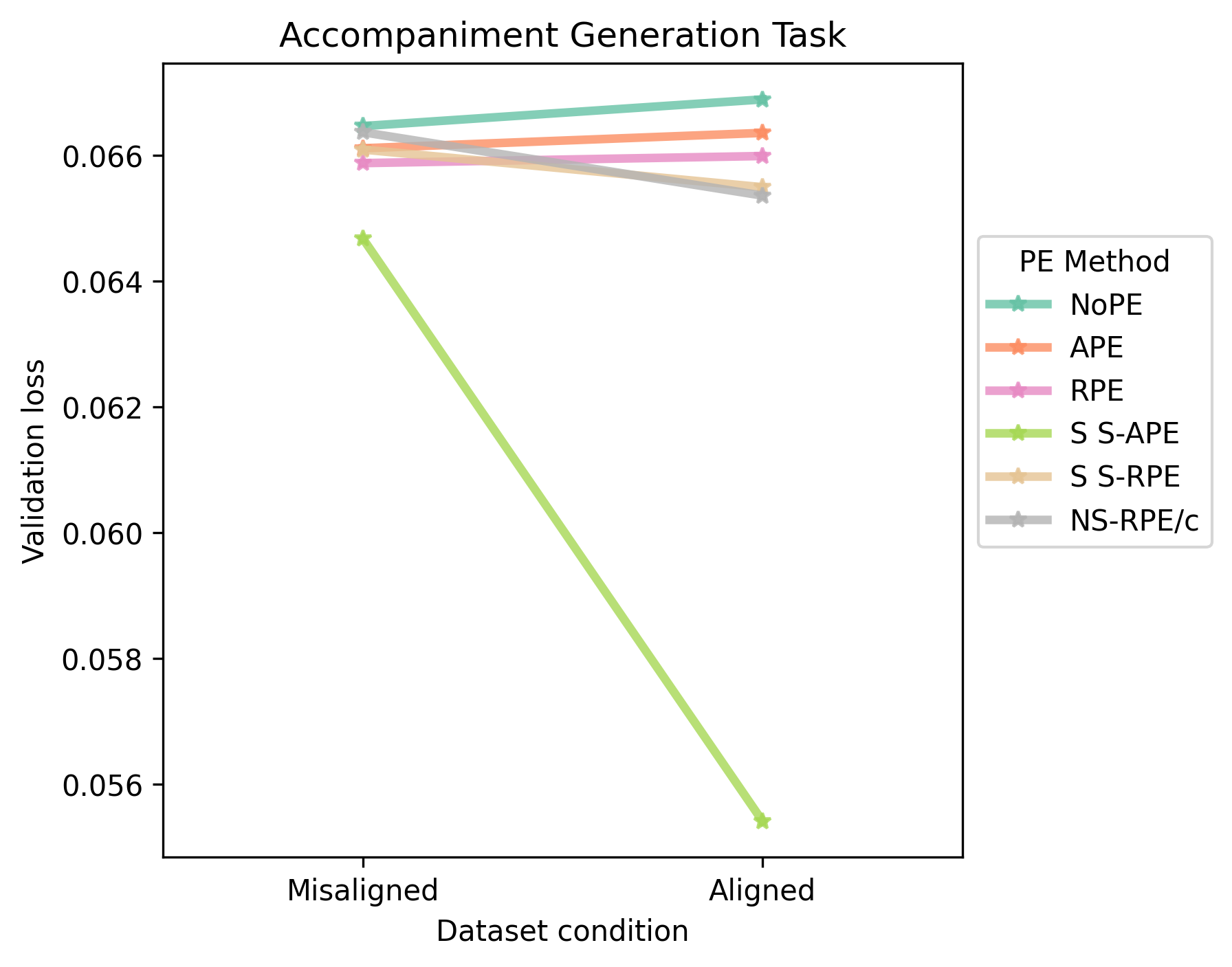
Generated Samples
Below, we give some good and bad examples of both the baseline methods and our proposed methods. The abbreviations are as follows:
- Baselines
-
NoPE: No Positional Encoding -
APE: Absolute Positional Encoding -
RPE: Relative Positional Encoding -
S-APE/b: SymphonyNet -
S-RPE/b: RIPO Attention
-
- Our Methods
-
L S-APE: StructureAPE with learnable embedding -
S S-APE: StructureAPE with sinusoidal embedding -
L S-RPE: StructureRPE with learnable embedding -
S S-RPE: StructureRPE with sinusoidal embedding -
NS-RPE/c: StructureRPE with nonstationary kernel on chord labels -
NS-RPE/s: StructureRPE with nonstationary kernel on section labels
-
We only use the sinusoidal embedding with the NS-* variants because of constraints on computational capacity.
Along with the samples, we also plot the self-similarity matrices depicting the structure of the corresponding song.
Next-timestep Prediction
Good Examples
Baselines
NoPE 

APE 

RPE 

S-APE/b 

S-RPE/b 

Our Methods
L S-APE 

S S-APE 

L S-RPE 

S S-RPE/b 

NS-RPE/c 

NS-RPE/s 

Bad Examples
Baselines
NoPE 

APE 

RPE 

S-APE/b 

S-RPE/b 

Our Methods
L S-APE 

S S-APE 

L S-RPE 

S S-RPE/b 

NS-RPE/c 

NS-RPE/s 

Accompaniment Generation
Besides the target and the prediction, we provide the melody track to give a sense of what the music sounds like without the accompaniment track. You can find the melody track under the name of each method.
Good Examples
Baselines
NoPE 

APE 

RPE 

S-APE/b 

S-RPE/b 

Our Methods
L S-APE 

S S-APE 

L S-RPE 

S S-RPE 

NS-RPE/c 

NS-RPE/s 

Bad Examples
Baselines
NoPE 

APE 

RPE 

S-APE/b 

S-RPE/b 

Our Methods
L S-APE 

S S-APE 

L S-RPE 

S S-RPE 

NS-RPE/c 

NS-RPE/s 
